
Do impossible fitted values really make LPM bad?
Published:
It is an extremely common argument in sociology that the linear probability model (LPM) is bad for modeling binary outcomes because it can produce fitted probabilities smaller than 0 or larger than 1. This argument is commonly used to justify the use of logit (or probit). But the fact that LPM can produce impossible fitted values while logit cannot actually favors LPM. Here’s why.
For a binary $Y$, consider the conditional probability function $Pr(Y=1 \mid X)$, which is what both LPM and logit try to estimate. Importantly, in the data we have, $X$ can take only some values. For example, if $X$ is a binary racial indicator, it can only be 0 or 1. If $X$ is students’ SAT scores, it can only be between 400 and 1600. If $X$ is one’s total wealth, it can vary from large negative values for those in debt to large positive values, but in any given dataset it has a limited range.
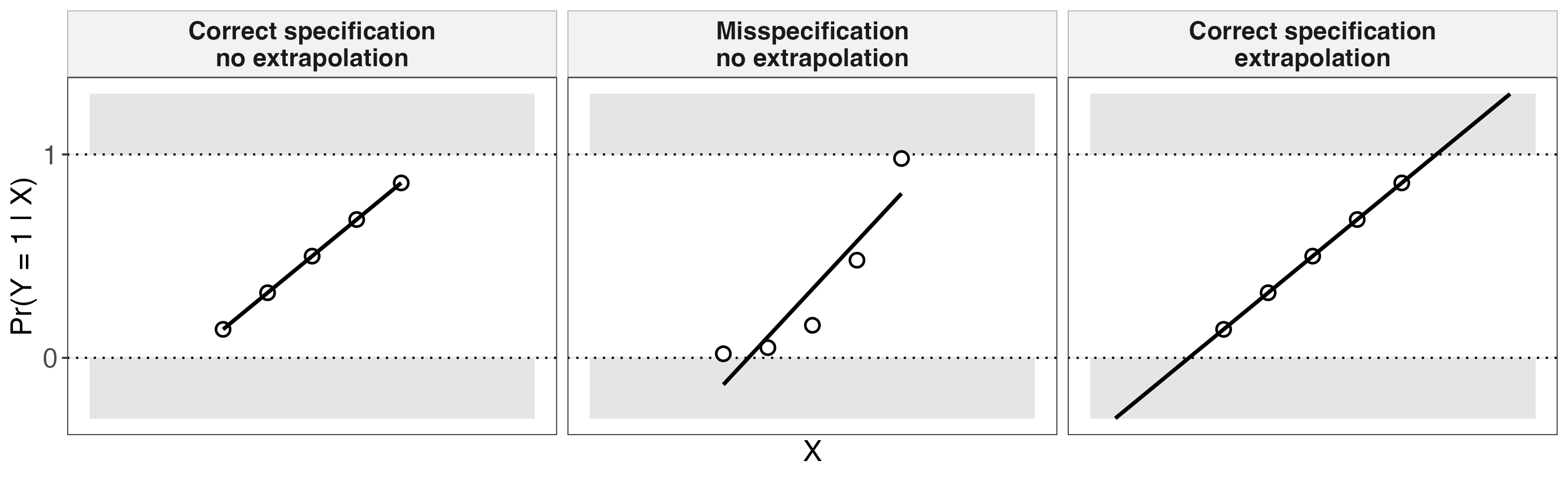
LPM produces impossible fitted values only if there is either misspecification or extrapolation. Misspecification means that the conditional probability function $Pr(Y=1 \mid X)$ has a form that cannot be captured by the LPM used. For example, if $Pr(Y=1 \mid X)=X^2$, then an LPM that regresses $Y$ on $X$ alone will not be able to fit the function correctly. Extrapolation means that we are plugging in values of $X$ that are outside the range of $X$ we observe in the data. The plots below show how misspecification and extrapolation can lead to impossible fitted values for LPM. The dots are true values of $Pr(Y=1 \mid X)$ (conditional probabilities, not individual-level data on $Y$), and the line is LPM fitted values.
What happens if we use logit instead? As shown below, even when misspecified or extrapolated, logit does not produce impossible fitted probabilities. This is because the logit function is mechanically bounded between 0 and 1.
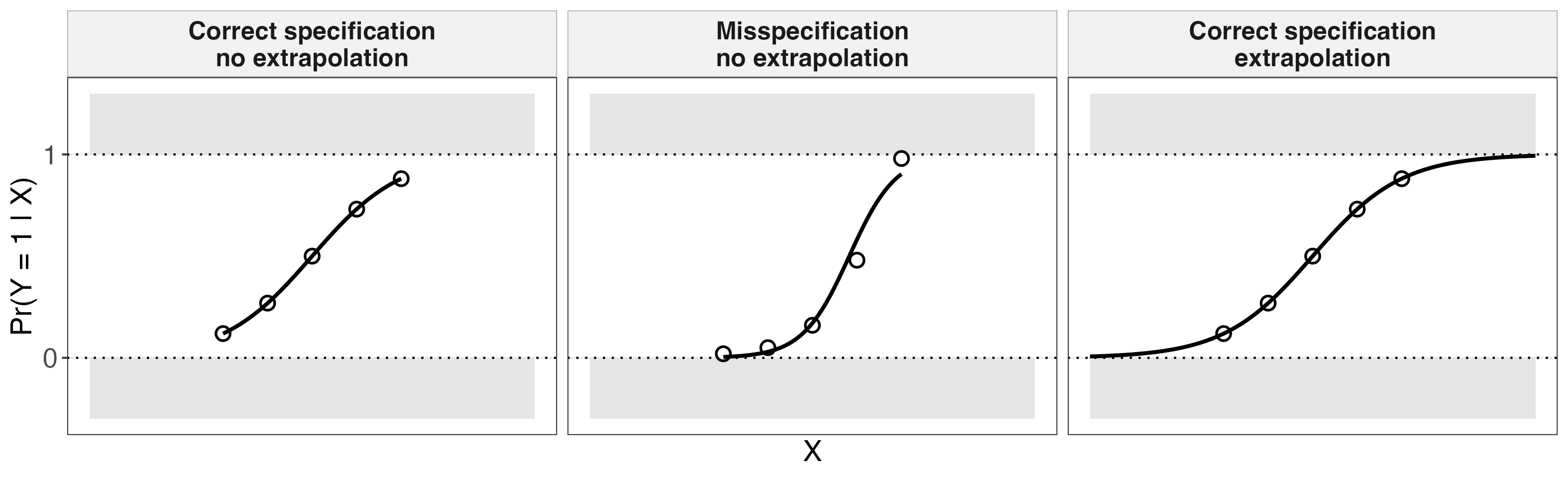
Is this a good thing or a bad thing? First, logit is not inherently more likely to be correctly specified. Without a theory about how the world generally works, there is no general reason to expect logit to be right when LPM is wrong. Second, logit is not inherently more robust to extrapolation. When we extrapolate without an explicit theory about how what we know extends to what we don’t know, we are doing nothing more than pure guessing. For example, we would be asking, what is the probability of attending Harvard for someone with an SAT score of 1800? The information is simply not there, regardless of what model we use.
Hence, when we are either wrong about the functional form or making uneducated guesses, LPM at least sometimes alerts us by producing impossible fitted values. In contrast, logit always looks right even when something is wrong. We would be shooting the messenger by ditching LPM for logit solely on the grounds of impossible predicted values.
If you have a theory about $Pr(Y=1 \mid X)$ that justifies either LPM or logit, you should by all means follow your theory. Without such a theory, the best one can do is follow the data. There are infinitely many possibilities for what $Pr(Y=1 \mid X)$ looks like. Many functional forms cannot be correctly captured by either LPM or logit. Fortunately, we can let the machine flexibly learn the functional form rather than choosing a particular parametric model ourselves. If you are thinking, “but I want a coefficient that I can interpret, machine learning is too black-box for me,” please check out this wonderful paper in ASR “What Is Your Estimand? Defining the Target Quantity Connects Statistical Evidence to Theory”.
P.S. There is a caveat. Above, I discussed everything assuming that we have a large enough sample for the model fits to have converged to their population limits. Hence, when the model is correctly specified, we can treat the fitted values as the population conditional probabilities $Pr(Y=1 \mid X)$. When the sample size is not large enough, even without misspecification or extrapolation, LPM can produce impossible fitted values by chance. In that case, LPM will not be a good messenger, which puts it on an equal footing with logit.
Leave a Comment